Eén van de belangrijkste principes van de Algemene verordening gegevensbescherming (AVG) is dataminimalisatie.(1) Persoonsgegevens mogen niet langer bewaard dan strikt noodzakelijk voor het bewerkstelligen van het doel waarvoor ze verzameld zijn.(2) Dat is nogal wat. Kijk naar uw eigen zolder of garage: het weggooien van spullen zit niet in onze natuur.
coauteur: Muller, Peter (e-Tomic)
“Wie weet heb ik het nog eens nodig” en “opruimen is saai”. U hoort het uzelf en uw kinderen al zeggen. Hetzelfde geldt voor bedrijven en zeker voor IT'ers. Bedrijven zijn erop gericht om zaken te kunnen verantwoorden. Voor rapportages, een audit of voor een rechtszaak. Met systemen is het niet anders. IT'ers zijn erop gericht om een situatie te kunnen reproduceren, en vooral géén data te verliezen.
De AVG vraagt dus een tegengestelde beweging: het systematisch weggooien van gegevens. Weggooien is één, het op systematische wijze doen een ander. Dat laatste is van levensbelang, want te veel persoonsgegevens weggooien kwalificeert als een ‘datalek’; eveneens een vergrijp in het kader van de AVG.
Het ontwerpen van een ‘systeem’ voor het weggooien van gegevens bestaat uit drie stappen:
Bewaartermijnen. Vaststellen hoe lang, welke persoonsgegevens bewaard moeten worden.
Data-inventarisatie. Inventariseren welke persoonsgegevens waar en met welk doel bewaard worden.
IT en processen. Implementeren van functionaliteit, tools, processen en procedures om persoonsgegevens op tijd te wissen of te anonimiseren.
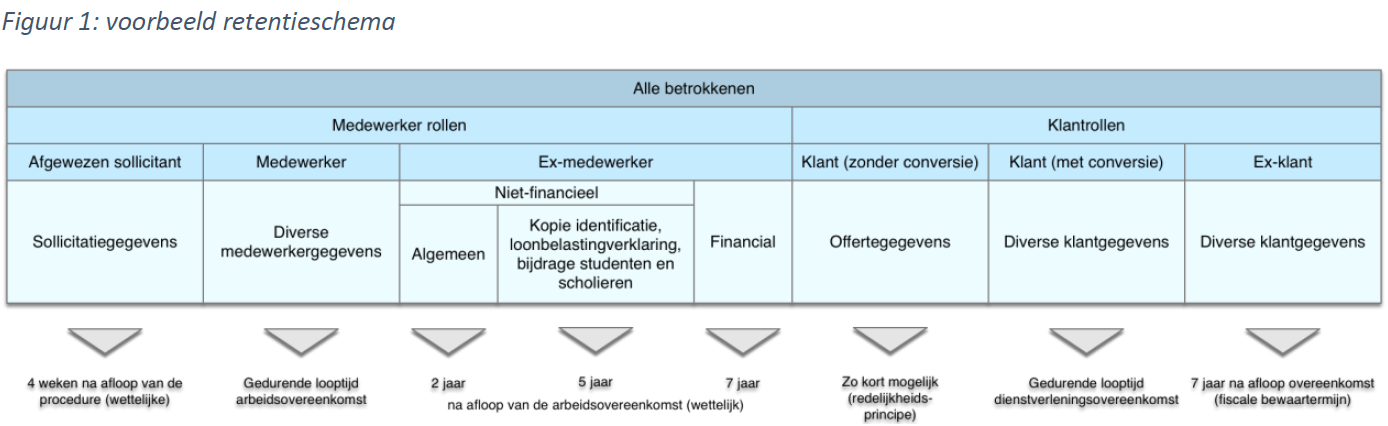
Niet langer dan strikt noodzakelijk. Dat is het criterium. Maar wat betekent dit concreet? Er zijn een paar basisprincipes die kunnen helpen bij het opstellen van een zogenoemd ‘retentie schema’ (zie Figuur 1). Vertrekpunt is dat het noodzakelijkheidscriterium grotendeels valt terug te voeren op de wettelijke grondslag voor het verzamelen van gegevens. De belangrijkste grondslagen zijn:
het voldoen aan wettelijke verplichtingen;
het aangaan en uitvoeren van een overeenkomst; en
toestemming van de betrokkene (medewerker of klant).
(Klik op de afbeelding voor een groter formaat)
Door de bewaartermijn voor bepaalde categorieën van gegevens vast te stellen op de wettelijke minimale of maximale bewaartermijn (bijvoorbeeld de fiscale bewaartermijn van zeven jaar voor financiële gegevens) kan een belangrijk deel van het retentieschema worden ingevuld.
De bewaartermijn hangt samen met de rol van de betrokkene (de natuurlijk persoon waarvan informatie worden verwerkt). In de regel heeft ieder bedrijf te maken met twee categorieën van betrokkenen: medewerkers en klanten. Klanten zijn er in twee vormen: consumenten en bedrijven. Laatstgenoemde betreft geen persoonsinformatie, behalve als de rechtsvorm een eenmanszaak is.
Medewerkers en klanten zijn weer verder onder te verdelen afhankelijk van hun rol. Voor de persoonsgegevens van sollicitanten, medewerkers en ex-medewerkers gelden verschillende bewaartermijnen. Hetzelfde geldt voor aspirant klanten, klanten en ex-klanten. Zolang er sprake is van een arbeids- of dienstverleningsovereenkomst (c.q. abonnement of lidmaatschap) is er grond voor het bewaren van (bijna alle) gegevens, zoals oude orders, mutaties in klantgegevens, etc. Het is immers eveneens in het belang van de klant om een totaal ‘klantbeeld’ te hebben.
Zolang u toestemming heeft van de betrokkene mag u de gegevens verwerken en dus bewaren. Dit is en blijft een wankele basis. Toestemming kan immers ook worden ingetrokken en dan valt de basis voor de verwerking weg. Daarnaast hebben betrokkenen in het kader van de AVG een aantal rechten (zoals het recht op vergetelheid) die de bewaartermijn kunnen verkorten.
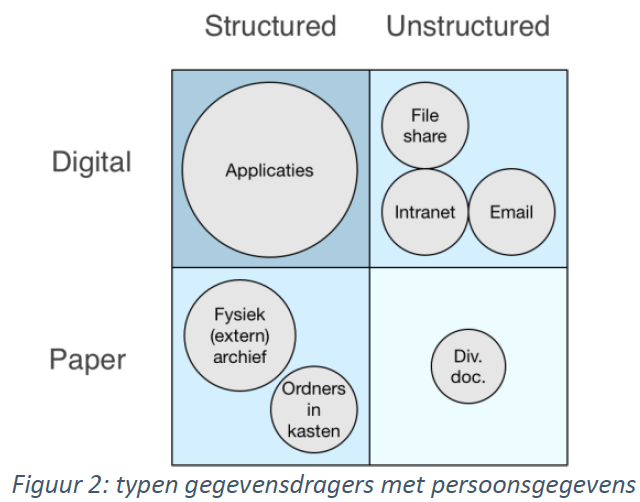
Wat ligt er allemaal op zolder? Dit ècht goed in kaart brengen is een monstrueuze klus. Zeker gezien de verscheidenheid aan gegevensdragers. Deze zijn in te delen langs de volgende twee dimensies (zie Figuur 2):
Gestructureerd versus ongestructureerd.
Digitaal versus fysiek.
(Klik op de afbeelding voor een groter formaat)
In het kwadrant linksboven bevinden zich applicaties die de kern van het bedrijfsproces ondersteunen: front- mid- en backofficesystemen, CRM, outputmanagement en meer. De meeste van deze applicaties beschikken over een database, waarin gegevens in gestructureerde, doorzoekbare records zijn opgeslagen. Aandachtspunt is de aanwezigheid van gebruikersdatabases of logfiles met persoonsgegevens. Een ander aandachtspunt is gegevensuitwisseling tussen applicaties middels ‘tussenbestanden’ die vaak permanent op de file share worden opgeslagen.
In het kwadrant rechtsboven staan applicaties en systemen met ongestructureerde data: Document Management systeem, file share, intranet en email. Kanttekening hierbij is dat het Document Management systeem weliswaar ongestructureerde gegevens bevat (scans, PDF-, Word documenten, etc.), maar dat deze wel geïndexeerd en dus doorzoekbaar zijn. Ongestructureerde gegevens zijn lastig te schonen. Er is geen magische knop in Outlook of Bestandsbeheer waarmee alle emails of documenten van klant x kunnen worden geschoond.
In het kwadrant linksonder bevinden zich de fysieke archieven (in dozen of ordners) met, als u geluk heeft, een index van de inhoud. Schoning van individuele (klant)dossier in deze archieven is zeer bewerkelijk: periodiek opvragen en doorlopen van alle dozen of ordners, filteren en weggooien wat weg moet, terugstoppen wat behouden moet blijven, etc. Een arbeidsintensief en haast onmogelijke opgave. Vaak blijkt dat dozen in een (extern)archief onvoldoende kenmerken hebben om gegevens terug te vinden. Hierdoor is het onmogelijk bewaartermijnen te kunnen naleven.
In het kwadrant rechtsonder bevindt zich een amalgaam van documenten in bureaulades, stapels in kasten, etc. Misschien wel de makkelijkste categorie: niets mee doen of integraal weggooien.
Er zijn verschillende manieren om de zolder op te ruimen. De ene heeft een meer systematisch en structureel karakter dan de andere. Onderstaande aanpak gaat uit van een fundamentele aanpak waarbij de schoning of anonimisering zo veel mogelijk automatisch plaatsvindt.
De aanpak bestaat uit de volgende onderdelen:
Ontwikkeling van schonings- of anonimiseringsfunctionaliteit.
Digitalisering en vernietiging van fysieke archieven.
Reorganisatie en automatische scanning van de file share en intranet.
Automatische schoning van emails met persoonsgegevens.
Het ontwikkelen van degelijke functionaliteit is makkelijker gezegd dan gedaan. De meeste organisaties hebben meerdere (kern)applicaties die tezamen ‘ketens’ vormen waarin (persoons)gegevens worden verwerkt.
De applicaties moeten in samenhang worden bekeken. Het is zinloos om persoonsgegevens te anonimiseren als ze ’s nachts worden teruggezet dankzij de synchronisatie met een andere applicatie. Of als anonimisering resulteert in een storing omdat de gegevens niet langer voldoen aan de validatieregels die de technische interface met een andere applicatie stelt.
Bij de ontwikkeling van schonings- of anonimiseringsfunctionaliteit zijn drie aandachtspunten van belang:
Controle en validatie van de gegevensselectie.
Rol c.q. statusafhankelijke bewaartermijnen.
Uniforme anonimiseringsstrategie.
Weg is weg! Deïdentificatie van persoonsgegevens is onomkeerbaar. Dat is best spannend. Zeker als het bedrijfskritische klantgegevens betreft. Hoe weet u of u niet te veel (of te weinig) weggooit? Het antwoord op deze vraag is een procedure met ‘checks and balances’. De te deïdentificeren records worden automatisch geselecteerd. De selectiefunctionaliteit wordt opgenomen in de regressietest van toekomstige releases.
De selectie wordt handmatig en visueel gecontroleerd volgens het vierogenprincipe, waarbij tevens records kunnen worden uitgesloten (b.v. in geval van een juridisch dispuut). Deze controle vindt plaats aan de hand van een plausibiliteitrapport dat aangeeft hoeveel records normaal gesproken geschoond zouden moeten worden. Dit rapport komt langs een andere weg tot stand en ‘trianguleert’ de uitkomst.
De bewaartermijn van persoonsgegevens is in veel gevallen afhankelijk van de rol van de betrokkene. Of beter geformuleerd: afhankelijk van het moment waarop de rol van de betrokkene gewijzigd is (b.v. het moment waarop een medewerker uit dienst is gegaan).
Dit maakt dat applicaties die wel persoonsgegevens bevatten, maar niet weten wanneer de rolwijziging is opgetreden en niet gesynchroniseerd zijn met een applicatie die het wel ‘weet’, deze gegevens niet zelfstandig kunnen schonen of anonimiseren. Deze applicaties dienen een signaal te ontvangen vanuit het kernsysteem dat de status wel kent.
Relatierecords weggooien of anonimiseren heeft hetzelfde effect: gegevens worden onomkeerbaar gedeïdentificeerd. Over het algemeen verdient anonimisering de voorkeur. Geanonimiseerde gegevens kunnen nog gebruikt worden voor analysedoeleinden en verwijdering van relatierecords kan leiden tot een corrupte database.
Echter, anonimisering werkt alleen als alle applicaties dezelfde strategie hanteren. Als in de ene applicatie postcode behouden blijft en in de andere geboortedatum, dan kan de betrokkene nog steeds geïdentificeerd worden door beide records via een sleutel (b.v. relatie- of contractnummer) aan elkaar te koppelen. In wezen is dan sprake van pseudonimisering, in plaats van anonimisering.
De keuze voor een uniforme anonimiseringsstrategie is dus van belang. Het verdient aanbeveling om de strategie zo te kiezen dat deze ook gebruikt kan worden om ontwikkel- en testomgevingen te pseudonimiseren. IT-medewerkers hebben dan niet langer inzicht in persoonsgegevens (een ander vereiste vanuit de AVG).
Het klinkt tegenstrijdig: om persoonsgegevens te kunnen schonen moeten ze eerst gedigitaliseerd en gecentraliseerd worden. Digitalisering is nodig om documenten automatisch te kunnen weggooien en centralisatie is van belang om de schoning efficiënt in te kunnen inrichten op basis van een signaalfunctie vanuit de backoffice- of CRM-applicatie.
Digitalisering en centralisatie vereisen de implementatie van een Document Management systeem in combinatie met een ‘scanstraat’. Dit is een project op zich en het voert te ver om hier te beschrijven wat hierbij komt kijken. Vast staat dat er een hoop keuzes te maken zijn. Huidige fysieke archieven scannen of ze ‘eruit laten lopen’? Afscherming van ‘dood archief’ via Compliance manager? Allemaal keuzes die zorgvuldig gemaakt en gedocumenteerd moeten worden.
Dit artikel is ook te vinden in het dossier Verantwoordingsplicht
Meer artikelen van PrivacyTeam








